Visual Relationship Detection using Scene Graphs - A Survey
1. Introduction
The past decade has seen a steady increase in the usage of deep learning techniques for solving various tasks, such as Image Recognition [38,41,18,19], Object Recognition [15,14,34,33] and Image Segmentation [35,54,6,5], to name a few. The ultimate aim of all these tasks has been to
learn even more powerful representations from the input data by solving even more challenging tasks like Image Captioning [48,23,30], Visual Question Answering [3,29,1].
As a result, to describe the image features and object relationships in an even more explicit and structured way, Scene Graphs [21] were proposed. Scene graphs capture the detailed semantics of visual scenes by explicitly modeling objects along with their attributes and relationships with
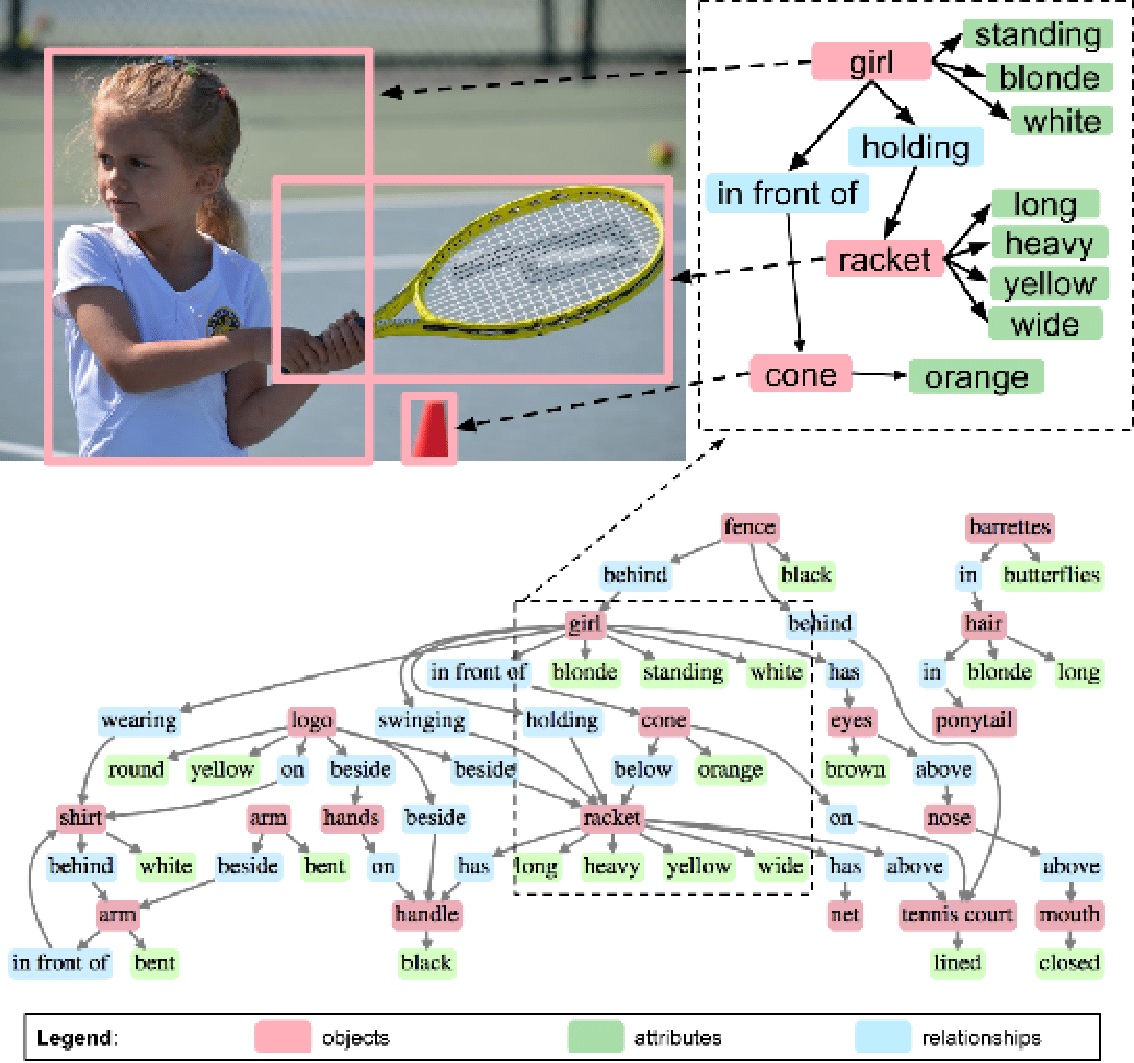
other objects. With the nodes representing the objects in the scene and the edges linking them representing the relationships between the various objects in a dynamic graphical structure, we get a rich representation of the given scene in an image. An example for the same can be seen in Fig. 1, where the objects, their attributes and the relationships are being represented in a graphical way.
However, such rich representational power does come with an evident challenge of its generation. The pipeline for Scene Graph Generation (SGG) [47,26,25] can be broken down into several steps: object detection for node creation, graph generation using the created nodes and an iterative updation of the relationship and node features to obtain the desired scene graph. The interdependence of the subcomponents of the pipeline for the task of scene graph generation makes it a much more complicated task than the individual tasks of object detection, graph creation, etc.
To make the readers clear with the task and the terminologies associated with the task, we will be covering the basic definition of the problem statement and also discuss upon the various methods in the past literature used to solve the same. We also give a taxonomy to classify the work done in this field, which we believe would help to streamline the future work in this area. Lastly, we also discuss upon the past trend and future directions for research in this field. With such wide applicability, we feel this comprehensive evaluation of the past work is required for further advancement in this field, and at the same time give the required exposure to someone starting in this field.

Figure 1: An example of a scene graph taken from [21]. The scene graph encodes objects ("girl"), attributes ("girl is blonde") and relationships ("girl holding racket").
2. Scene Graph Definition
Before proceeding further, we would like to formally define the term Scene Graph and the various components associated with it.
A Scene Graph is a graphical data structure that describes the contents of a scene. A scene graph encodes object instances, attributes of objects, and relationships between objects. Given a set of object classes
We will now outline the general pipeline followed by most of the previous works to give the readers a basic understanding of the various components of the Scene Graph Generation process. A diagrammatic representation for the whole process can also be seen in Fig. 2.

Figure 2: A basic pipeline for the scene graph generation process, adapted from [47]. Given an image, an RPN block (a) is used to extract the object proposals along with their features, that are used to create a candidate graph (b). After the generation of a candidate graph, a feature refining module ( c ) is used to refine the features further. Once the refinement is done, a scene graph (d) is inferred according to the node and edge features. Subsequently, the model is trained using a loss function on the dataset.
2.1 Region Proposal Module
This module proposes multiple objects that are identifiable within a particular image. RPN [34] is one of the popular choices, efficiently scans every location in the image in order to assess whether further processing needs to be carried out in a given region. For this purpose, it outputs k bounding box proposals per image, each with an associated object confidence score. Afterwards, RPN ranks region boxes (called anchors) and proposes the ones most likely containing objects. Once we have the region proposals, they can be used further for graph construction and feature extraction.
2.2 Graph Construction Module
This module initializes the relationship features between the object pairs, usually through a Fully Connected Graph, where every object proposal is considered as related to another object proposal, even though some relations like tire and a car maybe more prominent than others like tire and a building. Once the initial graph is created with some dummy relations between the detected objects, we move towards refinement of the node and edge features using the Feature Refinement Module.
2.3 Feature Refining Module
Feature Refining Module is the most important and extensively studied module in Scene Graph Generation. Various methods [47,26,12,8,25] were introduced from time to time to leverage its full capacity. The idea is to incorporate contextual information either explicitly or implicitly so that the detection process for objects and relations becomes more context-dependent. The intuition behind feature refining is the superior dependencies among
2.4 Scene Graph Inference and Loss Functions
With the node and edge features refined, we move onto inferring the final scene graph, which encodes the visual relationships in our scene. The inference task basically transforms the refined features to one-hot vectors for the object and predicate choices in the training dataset. Once the scene graph is obtained, a loss function is defined which usually calculates the likelihood between the obtained object-relation labels and the true labels in the training dataset.
3. Taxonomy of scene graph generation models
Scene Graph Generation, being a relatively new research field, hasn’t seen many enormous break-throughs till now. Rather than concrete structural changes in the model architecture, most of the research in this field can be classified in the terms of the problem that they are mainly addressing in the SGG task . The four problems in the task that the past literature has majorly targeted, thus becoming the basis of our classification, are Efficient Graph Features Refinement, Efficient Graph Generation, Long-tailed Dataset Distribution and Efficient Loss Function Definition. As summarized in Table 1, many works have targeted two or more of the problems specified at the same time.

Table 1: Taxonomy for the various Scene Graph Generation (SGG) methods. The tick in a particular
column represents the problem that the method tries to target through its main contributions.
3.1 Efficient Graph Features Refinement
Motivation
Methodology
To be more specific if
Where

Figure 3 The figures represent the feature refining steps for [47]. The figure represents the Feature Refining Module proposed in [47], with major concentration on the message pooling module for information interchange between the node and edge GRUs
Graph R-CNN [49] proposed a variant of attentional GCN to propagate higher-order context throughout the graph and enable per-node edge attentions, allowing the model to learn to modulate information flow across unreliable and unlikely edges.
MotifNet [52] builds on the hypothesis that the classes of the object pair are highly indicative of the relationship between them, while the reverse is not true. This is an example of the problem of Bias in Dataset, which will be explored further in section 3.3. Hence rather than following the
traditional paradigm of bidirectional information propagation between object and relationships, they predict graph elements by staging bounding box predictions, object classifications, and relationships such that the global context encoding of all previous stages establishes a rich context for predicting subsequent stages. Hence the network decomposes the probability of a graph
This kind of strong dependence assumption helps the model to capture the global context better. To model this, they have used BiLSTM for object context encoding and LSTMs for object context decoding. The obtained object classes are passed to a BiLSTM which encodes relationship context and predicts the predicates.

Figure 4 The framework of the VCTree model [43]. Visual features are extracted from proposals, and a dynamic VCTree is constructed using a learnable score matrix. The tree structure is used to encode the object-level visual context, which will be decoded for each specific end-task. In context encoding ( c ), the right branches (blue) indicate parallel contexts, and left ones (red) indicate hierarchical contexts. Parameters in stages ( c ) & (d) are trained by supervised learning, while those in stage (b) use REINFORCE with a self-critic baseline.
One of the underlying problems with these feature representations discussed so far is the lack of discriminative power between hierarchical relations in these. To solve this problem, [43] proposed a tree structure encoding for the node and edge features for both the SGG and VQA task, having it explicitly encode any hierarchical and parallel relations between objects in its structure. To construct the tree, a score matrix S is first calculated to approximate the validity between object-pairs, with
where
where
For Object Context Encoding,
Once the embeddings are created, decoding takes place, with the object class of a node dependant on its parent. For relationship extraction, three pairwise features are extracted for each object pair, namely context feature, bounding box feature, and RoIAlign feature, and the final predicate classification is done by combining all of them. Since the score matrix
3.2 Efficient Graph Generation Task
Motivation

Figure 5 Pipeline of Factorizable-Net [25]. (1) RPN is used for object region proposals, which shares the base CNN with other parts. (2) Given the region proposal, objects are grouped into pairs to build up a fully-connected graph, where each pair of objects are connected with two directed edges. (3) Edges that refer to similar phrase regions are merged into subgraphs, and a more concise connection graph is generated. (4) ROI-Pooling is employed to obtain the corresponding features~(2-D feature maps for subgraph and feature vectors for objects). (5) Messages are passed between subgraph and object features along with the factorized connection graph for feature refinement. (6) Objects are predicted from the object features and predicates are inferred based on the object features as well as the subgraph features. Green, red and yellow items refer to the subgraph, object and predicate respectively.
Methodology

Figure 6 Left: SMP structure for object/subgraph feature refining. Right: SRI Module for predicate recognition. Green, red and yellow refer to the subgraphs, objects, and predicates respectively.
While the above technique focuses on reducing the number of relations by not ignoring any relationship, Graph RCNN [49] proposes a novel Relation Proposal Network (RePN) which efficiently computes relatedness scores between object pairs and prunes out unlikely relations based on cosine similarity of projected features followed by Non-max suppression. Once a sparse graph is obtained, attentional GCNs are used to refine the features.
3.3 Long-tailed Dataset Distribution
Motivation

Figure 7: Visual Relationships have a long tail (left) of infrequent relationships. Current models only focus on the top 50 relationships (middle) in the Visual Genome dataset, which all have thousands of labeled instances. This ignores more than 98% of the relationships with few labeled instances (right, top/table).
Methodology
While the above model worked on using statistical information to get the desired result, few-shot learning and semi-supervised techniques have also been used in various literature works to treat the dataset imbalance. [9] and [11] enlist some ways to solve the long-tail problem in the SGG task by taking inspiration from the recent advances in semi-supervised and few-shot learning techniques. [9] proposes a semi-supervised approach by using image-agnostic features such as object labels and relative spatial object locations from a very small set of labeled relationship instances to assign probabilistic labels to relationships in unlabelled images. For this, image-agnostic features are extracted from objects in the labeled set
While the above technique used a model to label unlabeled data, [11] proposes a way to utilize the recent advances in few-shot learning for learning object representations from frequent categories and using these for few-shot prediction of rare classes. This is done by using a mechanism to create object representations that encode relationships afforded by the object. The idea is if a subject representation is transformed by a specific predicate, the resulting object representation should be close to other objects that afford similar relationships with the subject. For example, if we transform the subject, person, with the predicate riding, the resulting object representation should be close to the representations of objects that can be ridden and also at the same time be spatially below the subject. For such transformations, we deal with predicates as functions, dividing it into two individual functions: a forward function that transforms the subject representation into object and an inverse function that transforms the object representation back into subject. Each of these is further divided into two components: a spatial component (
While all of the above techniques required training from scratch to solve the problem and essentially propose a complete model in themselves, [44] proposed a unique framework that can be used on top of any trained SGG model to deal with the bias present in the dataset which eventually leads to the presence of a long-tail distribution in them. The framework, utilizing the concepts of causal inference, can be attached on top of any model to make the model’s relationship predictions less biased. A visual example of the framework proposed can also be seen in Fig. 8. It proposes to empower machines with the ability of counterfactual causality to pursue the "main effect" in unbiased prediction: "If I had not seen the content, would I still make the same prediction".

Figure 8: (Left) Represents the visual example of the framework proposed in [44]; (Right) Represents the causal graphs of the normal and counterfactual scene.
The novel unbiased SGG method proposed in [44] is based on the Total Direct Effect (TDE) analysis framework in causal inference [31]. A visualization of the causal graph for the whole process can also be seen in Fig. 8, which represents both the pipeline of biased training and that of unbiased training suggested in [44]. Hence to have an unbiased prediction by causal effects, we will intervene in the value of
This gives logits free from context bias.
3.4 Efficient Loss Function Definition
Motivation
Methodology
-
Class-Agnostic Loss Used for contrasting positive/negative pairs regardless of their relation and adds contrastive supervision for generic cases. For a subject indexed by
and an object indexed by , the margins to maximize can be written as: whereand represent sets of objects related to and notrelated to subject , and a similar definition for , and . Finally, this loss can be defined as: whereis the number of annotated entities and is the margin threshold. -
Entity Class Aware Loss Used for solving the Entity Instance Confusion and can be taken as an extension of the above loss where class
is defined when populating positive and negative sets and . Hence the margins are defined in a similar way as Eq. 7, where rather than , is used to refer to class instances. Also, the definition of is pretty similar to Eq. 8, taking into account the margins specified here. -
Predicate Class Aware Loss Used for solving the Proximal Relationship Ambiguity problem and can be taken as an extension of the above two losses where relationship e is defined when populating positive and negative sets
and . Hence the margins are defined in a similar way as Eq. 7, where rather than , is used to refer to a set of subject-object pairs where ground truth predicate between and is . Also, the definition of is pretty similar to Eq. 8, taking into account the margins specified here.
A linear combination of all these losses, along with a standard cross-entropy makes up the final objective loss. In this way, [53] takes care of some of the edge cases having the problem types stated above. Another problem specified in [7] is that of Graph Coherency and Local-Sensitivity in the objective. While Graph Coherency means that the quality of the scene graph should be at graph-level and the detected objects and relationships should be contextually consistent, Local-Sensitivity means that the training objective should be sensitive to the changes of a single node. Hence, Counterfactual critic Multi-Agent Training (CMAT) [7] is proposed to meet both the requirements. In this, a novel communicative multi-agent model is designed, where objects are viewed as cooperative agents, and the action of each agent is to predict its object class labels. For the graph-coherent objective, the objective is defined as a graph-level reward (e.g., Recall@K [28] or SPICE [2]) and policy gradients [40] are used to optimize the non-differentiable objective, where the relationship model can be framed as a critic and the object classification model serves as a policy network. For the local-sensitive objective, a counterfactual baseline is subtracted from the graph level reward by varying the target agent and fixing the others before feeding into the critic. An example of these two problems can also be seen in Fig. 9.

Figure 9: (a) presents examples of the problem targeted in [7]; (b) presents the procedure for calculating the counterfactual baseline CB.
For a graph coherent training objective, each detected object is modeled as an agent whose action is to predict the object class labels
where
To incorporate local sensitive signals to the objective, a counterfactual critic approach is used, where the individual contribution of an agent is represented by subtracting counterfactual baseline
Here
Finally, the cross-entropy losses are also incorporated in the overall gradient along with gradients in Eq. 11.
4. Applications
Having dealt with the problem of Scene Graph Generation, the obvious question that comes into the reader’s mind is "why go through such trouble to create scene graphs to represent visual relationships in a scene?". Hence to make sense of all the work to improve the performance in the generation task, we are now going to delve into the various applications of scene graphs and how their rich representational power has been used to solve various downstream tasks such as VQA, Image Captioning, and many others.
4.1 Semantic Image Retrieval
Retrieving images by describing their contents is one of the most exciting applications of computer vision. An ideal system would allow people to search for images by specifying not only objects ("man" and "boat"), but also structured relationships ("man on boat") and attributes ("boat is white"). However as pointed out in [21], bringing this level of semantic reasoning to real-world scenes involves two main challenges: (1) interactions between objects in a scene can be highly complex, going beyond simple pairwise relations, and (2) the assumption of a closed universe where all classes are known beforehand does not hold.
Hence to tackle these problems, [21] proposes the use of scene graphs for the task. Replacing textual queries (used for retrieval) with scene graphs allows the queries to represent the visual relationships in a scene in an explicit way rather than relying on unstructured text for the task. The paper introduced a novel Conditional Random Field (CRF) model for retrieving the image from a given scene graph, outperforming retrieval methods based on low-level visual features.
Further work by [37] focuses on the fact that manual creation of scene graph is tough, hence working upon its automation by user encoding the relationships to parse the image description. The created scene graphs are used for image retrieval with the same CRF formulation as above. Here the scene graph creation acts as an intermediate step, rather than the input as in [21]. Even with textual query as the main input, they report almost the same performance for image retrieval when using human-constructed scene graphs. This result clearly implies a direct correlation between a more accurate image retrieval method and the Scene Graph Generation task.
4.2 Visual Question Answering
With the rich representational power of scene graphs and the dense & explicit relationships between various nodes (objects), its application and usage in the VQA task is a natural consequence. The usage of graphs instead of more typical representations (using CNNs for image feature extraction and LSTMs for word feature extraction) poses various advantages such as exploitation of the unordered nature of scene elements as well as the semantic relationships between them.
To exploit these advantages, [45] proposes a novel technique to solve this task by representing both the question and the image given by the user in the form of graphs. The training dataset used, being a synthetic one, already has object label information and their relationships for the scene graph to be a direct input, while the given question was parsed to form a graph. Thereafter, simple embeddings are generated for both nodes and edges of both the graphs and the features are then refined iteratively using a GRU. At the same time, pre-GRU embeddings are used to generate attention weights, which are used to align specific words in the question with particular elements of the scene. Once the attention weights and refined features are obtained, the weights are applied to the corresponding pairwise combinations of question and scene features. Finally with the help of non-linearities and weight vector layers, the sum of weighted features over the scene and question elements are taken step-by-step. This leads to the eventual generation of the answer vector, containing scores for the possible answers. The entire process can be seen in Fig. 10.

Figure 10: A pipeline for [45] on using scene graphs for VQA. The input is provided as a description of the scene and a parsed question. A recurrent unit (GRU) is associated with each node of both the graphs that updates the representation of each node over multiple iterations. Features from all object and all words are combined (concatenated) pairwise and they are weighted with a form of attention. This effectively matches elements between the question and the scene. The weighted sum of features is passed through a final classifier that predicts scores over a fixed set of candidate answers.
Apart from this, [43] describes a unique method of using a tree-structured representation for visual relationships. While the SGG part of the paper has already been discussed in Section 3, it can also be used for the VQA task by changing the VCTree Construction method to incorporate pairwise task dependancy
4.3 Image Captioning
Image captioning is the process of generating textual descriptions from an image. The process has moved from rule and template-based approaches to CNN and RNN based frameworks. There have been striking advances in the application of deep learning for image captioning, one of them being the use of scene graphs for image captioning. Scene graphs being a dense semantic representation of images have been used in several ways to accomplish the task of caption generation. MSDN [26] proposed to solve three visual tasks in one go, namely region captioning, scene graph generation, and object detection. It offered a joint message passing scheme so that each vision task can share information and hence leveraged the rich semantic representation capability of scene graphs for image
captioning.
From common understanding, it’s quite evident that modeling relationships between objects would
help represent and eventually describe an image. Still, the field was unexplored until [51] used scene graph representation of an image to encode semantic information. The idea is to develop semantic and spatial graphs and encode them as feature vectors using GCN, so that the mutual correlations or interactions between objects are the natural basis for describing an image and caption generation.
A general problem with encode-decoder based caption generation is the gap between image and
sentence domains. Since scene graphs can be generated from both text and images, they can be adopted as an explicit representation to bridge the gap between the two domains [17,50]. In [17], the main idea was to use inductive bias as humans do, i.e., when we see the relation “person on bike,” it is natural to replace “on” with “ride” and infer “person riding bike on a road” even if the “road” is not evident. To incorporate such biases, a dictionary “D” based approach is adopted which is learned through the self-reconstruction of a sentence using scene graph encoder and decoder, i.e., they first generate a scene graph from the sentence [2], encode it using an encoder and then using the dictionary, refine the encoded features to obtain the sentence back. In the vision domain, a scene graph is constructed from an image [52] and encoded using another encoder, after which the learned dictionary is used to refine the features which can be decoded to provide captions.
Most works in image captioning generally deal with English captions; one major reason for that
is the availability of the dataset. To overcome the problem of unavailability of paired data, [50] provides a scene graph based approach for unpaired image captioning. Everything starts with the graph construction for both image [52] and caption [2]. Then with the help of the same encoder, both of these graphs are converted into feature maps. The features are aligned using a GAN-based method, and finally passed through a decoder for caption generation. The use of scene graphs in [17,50] proves the usability of scene graphs as a bridge between vision and text domain.
5. Performance Comparison
In this section, we are going to focus on quantitatively comparing the various SGG techniques described so far and also have a thorough comparative analysis of their performances. We will also define some common terms used for comparing these models. Firstly, we will be defining the various metrics commonly used in the literature, and also various newer alterations to them to make them more accurate. Secondly, we will be comparing the various models on the basis of these common metrics and notations.
Term Definitions Metrics are a measure of quantitative assessment and need to be well understood before using them for comparison. Following the same policy, we specify the metrics used and also the parameters for comparing several SGG approaches and architectures. Rather than accuracy or precision, Recall has become the de-facto choice as the model evaluation metric for the SGG task, owing to the presence of sparse annotations in the task’s dataset. The notation for recall that is followed is Recall@k abbreviated as R@k, which has become a default choice for comparison across various methods. The R@k metric measures the fraction of ground-truth relationship triplets (subject-predicate-object) that appear among the top-k most confident triplet predictions in an image, with the values of k being 50 and 100. SGG is a complex task and mostly evaluated on three parameters separately as described below:
- The predicate classification (PredCls) task is to predict the predicates of all pairwise relationships of a set of localized objects. This task examines the model’s performance on predicate classification in isolation from other factors.
- The scene graph classification (SGCls) or phrase classification (PhrCls) task is to predict the predicate as well as the object categories of the subject and the object in every pairwise relationship given a set of localized objects.
- The scene graph generation (SGGen) task is to simultaneously detect a set of objects and predict the predicate between each pair of the detected objects. An object is considered to be correctly detected if it has at least 0.5 IoU overlap with the ground-truth bounding box.
While almost all the SGG techniques report their results on these three parameters, these evaluation metrics are far from perfect and hence some modifications have been suggested in the past literature.
One of them is SGGen+ [49], which proposes to not only consider the triplets counted by SGGen, but also the recall of singletons and pairs (if any) ,i.e., it doesn’t penalize small mismatches much. For example, for a ground truth triplet < boy − wearing − shoes >, if boy is replaced with man, the SGGen score will be zero due to triplet mismatching, whereas in the case of SGGen+ it will be non-zero because of the correct classification of atleast the predicate and object. Another modification suggested is that of Mean Recall@k, abbreviated as mR@k [8,43] which tries to counter the problem of Long-tailed Dataset Distribution discussed earlier in Section 3. If one method performs well on several most frequent relationships, it can achieve a high R@k score, which makes it insufficient to measure performance on all relationships. This is where mean R@k shines, as it first computes the R@k for samples of each relationship and then averages over all relationships to obtain mR@K, and hence giving a more comprehensive performance evaluation for all relationships.
However, we don’t use SGGen+ and Mean Recall@K in Table 2 because the performance results of various models on these metrics are not available
Comparison The performance of the various SGG methods on Visual Genome [24], measured using the metrics described above, can be seen in Table 2. As can be clearly seen, the performance of all the methods with no-graph constraint is much better than ones with a graph constraint. Also, a clear decrease in the recall values as we move from PredClS to SGCls to SGGen indicates an eventual increase in the complexity of the respective metrics. While the earlier techniques such as iterative message passing [47] and MSDN [26] may have laid the groundwork for further work, their lower performance can clearly be attributed to their rudimentary message passing scheme. Even with a meagre improvement in accuracy reported by Graph R-CNN [49] and Factorizable Net [25], they are still able to reduce their inference time, with Factorizable Net reporting upto 3× speed boost as compared to earlier techniques. The poor performance by [16,9,11] can be explained by the fact that the usage of external knowledge, semi-supervised learning and few-shot learning gives a huge bump to the accuracy only when there is a limited annotated dataset. Hence, while all these three techniques outperform the other techniques on very less amount of data, their methodology does not lead to that big of a performance boost when dealing with the whole dataset. The clear winner in this "performance race" is evidently the usage of a modified loss function [53,7] and incorporating statistical dependencies [52,8,43] in the model.
However, one thing to keep in mind here is the fact that many of these techniques used only the most frequent relationships found in the dataset. This clearly is detrimental for the various downstream tasks that a scene graph can be used for and severely limits its applicability on real-world problems. Also, the usage of Recall@k instead of mean Recall@k severely handicaps the model’s performance and incorporates a bias in the end result as has been described earlier. The technique proposed in [44], which had the main contribution of more diverse predictions by removing the bias in predictions, report its results using only mean R@k (which is also why we were not able to report its results in the main table) and also beats all the other models in this evaluation metric. Furthermore, the other techniques using semi-supervised and few-shot learning methods [9,11], while performing poorly on R@k, would see a big bump in their accuracy when using mean R@k because of their main target being the tail classes, and have even reported to perform much better if the performance on just these infrequent classes is considered. Apart from this, the values reported in the table clearly indicate that the performance in scene graph generation is still far from human-level performance.

Table 2: Comparison on Visual Genome3 [24]. Results in the table are presented in their original work setting. Graph constraints refer to a single predicate prediction per object pair whereas, in the no-graph constraint setting, multiple predicates can be detected for each object pair.
6 Future Directions
While the model performance for scene graph generation and its subsequent usage in various downstream tasks has come a long way, there is still much work that needs to be done. In this section, we will be outlining the current trend of research in this field and also some of the possible directions in which it may lead to in the future.
Starting off, as can be seen from the previous section, there has been a shift in the usage of mean Recall@k instead of Recall@k, which can lead to a more "reliable" evaluation of models. The long-tailed distribution in existing datasets is undoubtedly a major problem that has been targeted in more and more recent works. Some of the recent techniques used meta-learning for long-tailed recognition [27] and a decoupled learning procedure [22], all of which can be further modified to be used for the long-tailed distribution problem in the context of relationship detection. One of the major reasons for the limited usage of Scene Graphs for downstream tasks like VQA, Image Captioning, etc., even with such rich representational power, has been due to the handicap imposed upon them by a biased dataset. Hence, targetting the long-tail of infrequent relationships for a more diverse prediction set has become increasingly important.
Another problem restricting the wide applicability of scene graphs is the lack of efficiency in training, which is due to the quadratic number of candidate relations between the detected objects. With only a few of the recent techniques [25,49] focussing on this, we believe that much more work can be done on this front. Expanding on the application areas of scene graphs, some recent techniques [4,12] develop a framework for utilizing the graph structure for 3D scene representation and construction, while the newly introduced Action Genome dataset [20] opens up the possibility of incorporating a spatio-temporal component to the scene graphs. With such exciting avenues still left to explore in this field, we firmly believe that Scene Graphs will be the next stepping stone for further narrowing down the gap between vision and language related tasks.
7. Conclusion
This paper presented a comprehensive survey on the various techniques that have been used in the past literature for the Scene Graph Generation task. We also outlined the various problems faced in this task and how different techniques focus on solving these problems to get a more accurate model. We reviewed the various datasets common to this task as well as how scene graphs have been used so far to solve various downstream tasks. We then compared the various SGG techniques and finally discussed the possible future directions of research in this field. With such a rich representational power, we believe that scene graphs can undoubtedly lead to state-of-the-art results in various vision and language domain tasks. Seeing the increasing research work in this field for getting more accurate and diverse scene graphs, this belief of ours should become a reality sooner than later.
Acknowledgments
We thank the invaluable inputs and suggestions by Dakshit Agrawal, Aarush Gupta and other members of Vision and Language Group, IIT Roorkee, that were integral for the successful completion of this project. We would also like to thank the Institute Computer Center (ICC) IIT Roorkee for providing us with computational resources.
References
[1] Peter Anderson et al. “Bottom-up and top-down attention for image captioning and visual question answering”. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2018, pp. 6077–6086.
[2] Peter Anderson et al. “Spice: Semantic propositional image caption evaluation”. In: European Conference on Computer Vision. Springer. 2016, pp. 382–398.
[3] Stanislaw Antol et al. “Vqa: Visual question answering”. In: Proceedings of the IEEE international conference on computer vision. 2015, pp. 2425–2433.
[4] Iro Armeni et al. “3D Scene Graph: A Structure for Unified Semantics, 3D Space, and Camera”. In: Proceedings of the IEEE International Conference on Computer Vision. 2019, pp. 5664–
5673.
[5] Liang-Chieh Chen et al. “Encoder-decoder with atrous separable convolution for semantic image segmentation”. In: Proceedings of the European conference on computer vision (ECCV). 2018, pp. 801–818.
[6] Liang-Chieh Chen et al. “Rethinking atrous convolution for semantic image segmentation”. In: arXiv preprint arXiv:1706.05587 (2017).
[7] Long Chen et al. “Counterfactual critic multi-agent training for scene graph generation”. In: Proceedings of the IEEE International Conference on Computer Vision. 2019, pp. 4613–4623.
[8] Tianshui Chen et al. “Knowledge-embedded routing network for scene graph generation”. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019, pp. 6163–6171.
[9] Vincent S Chen et al. “Scene graph prediction with limited labels”. In: Proceedings of the IEEE International Conference on Computer Vision. 2019, pp. 2580–2590.
[10] Bo Dai, Yuqi Zhang, and Dahua Lin. “Detecting visual relationships with deep relational networks”. In: Proceedings of the IEEE conference on computer vision and Pattern recognition. 2017, pp. 3076–3086.
[11] Apoorva Dornadula et al. “Visual Relationships as Functions: Enabling Few-Shot Scene Graph Prediction”. In: Proceedings of the IEEE International Conference on Computer Vision Workshops. 2019, pp. 0–0.
[12] Paul Gay, James Stuart, and Alessio Del Bue. “Visual Graphs from Motion (VGfM): Scene understanding with object geometry reasoning”. In: Asian Conference on Computer Vision. Springer. 2018, pp. 330–346.
[13] Shalini Ghosh et al. “Generating natural language explanations for visual question answering using scene graphs and visual attention”. In: arXiv preprint arXiv:1902.05715 (2019).
[14] Ross Girshick. “Fast r-cnn”. In: Proceedings of the IEEE international conference on computer vision. 2015, pp. 1440–1448.
[15] Ross Girshick et al. “Rich feature hierarchies for accurate object detection and semantic segmentation”. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2014, pp. 580–587.
[16] Jiuxiang Gu et al. “Scene graph generation with external knowledge and image reconstruction”. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019, pp. 1969–1978.
[17] Jiuxiang Gu et al. “Unpaired image captioning via scene graph alignments”. In: Proceedings of the IEEE International Conference on Computer Vision. 2019, pp. 10323–10332.
[18] Kaiming He et al. “Deep residual learning for image recognition”. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2016, pp. 770–778.
[19] Gao Huang et al. “Densely connected convolutional networks”. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2017, pp. 4700–4708.
[20] Jingwei Ji et al. “Action Genome: Actions as Composition of Spatio-temporal Scene Graphs”. In: arXiv preprint arXiv:1912.06992 (2019).
[21] Justin Johnson et al. “Image retrieval using scene graphs”. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2015, pp. 3668–3678.
[22] Bingyi Kang et al. “Decoupling representation and classifier for long-tailed recognition”. In: arXiv preprint arXiv:1910.09217 (2019).
[23] Andrej Karpathy and Li Fei-Fei. “Deep visual-semantic alignments for generating image descriptions”. In: Proceedings of the IEEE conference on computer vision and pattern recognition.
2015, pp. 3128–3137.
[24] Ranjay Krishna et al. “Visual genome: Connecting language and vision using crowdsourced dense image annotations”. In: International Journal of Computer Vision 123.1 (2017), pp. 32–73.
[25] Yikang Li et al. “Factorizable net: an efficient subgraph-based framework for scene graph generation”. In: Proceedings of the European Conference on Computer Vision (ECCV). 2018,
pp. 335–351.
[26] Yikang Li et al. “Scene graph generation from objects, phrases and region captions”. In: Proceedings of the IEEE International Conference on Computer Vision. 2017, pp. 1261–1270.
[27] Ziwei Liu et al. “Large-scale long-tailed recognition in an open world”. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019, pp. 2537–2546.
[28] Cewu Lu et al. “Visual relationship detection with language priors”. In: European conference on computer vision. Springer. 2016, pp. 852–869
[29] Jiasen Lu et al. “Hierarchical question-image co-attention for visual question answering”. In: Advances in neural information processing systems. 2016, pp. 289–297.
[30] Jiasen Lu et al. “Neural baby talk”. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2018, pp. 7219–7228.
[31] Judea Pearl. “Direct and indirect effects”. In: Proceedings of the 17th conference on uncertainty in artificial intelligence. Morgan Kaufmann Publishers Inc. 2001.
[32] Alexander J Ratner et al. “Data programming: Creating large training sets, quickly”. In: Advances in neural information processing systems. 2016, pp. 3567–3575.
[33] Joseph Redmon et al. “You only look once: Unified, real-time object detection”. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2016, pp. 779–788.
[34] Shaoqing Ren et al. “Faster r-cnn: Towards real-time object detection with region proposal networks”. In: Advances in neural information processing systems. 2015, pp. 91–99.
[35] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. “U-net: Convolutional networks for biomedical image segmentation”. In: International Conference on Medical image computing
and computer-assisted intervention. Springer. 2015, pp. 234–241.
[36] Benjamin Roth and Dietrich Klakow. “Combining generative and discriminative model scores for distant supervision”. In: Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing. 2013, pp. 24–29.
[37] Sebastian Schuster et al. “Generating semantically precise scene graphs from textual descriptions for improved image retrieval”. In: Proceedings of the fourth workshop on vision and
language. 2015, pp. 70–80.
[38] Karen Simonyan and Andrew Zisserman. “Very deep convolutional networks for large-scale image recognition”. In: arXiv preprint arXiv:1409.1556 (2014).
[39] Charles Sutton, Andrew McCallum, et al. “An introduction to conditional random fields”. In: Foundations and Trends® in Machine Learning 4.4 (2012), pp. 267–373.
[40] Richard S Sutton et al. “Policy gradient methods for reinforcement learning with function approximation”. In: Advances in neural information processing systems. 2000, pp. 1057–1063.
[41] Christian Szegedy et al. “Going deeper with convolutions”. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2015, pp. 1–9.
[42] Kai Sheng Tai, Richard Socher, and Christopher D Manning. “Improved semantic representations from tree-structured long short-term memory networks”. In: arXiv preprint arXiv:1503.00075 (2015).
[43] Kaihua Tang et al. “Learning to compose dynamic tree structures for visual contexts”. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019,pp. 6619–6628.
[44] Kaihua Tang et al. “Unbiased Scene Graph Generation from Biased Training”. In: arXiv preprint arXiv:2002.11949 (2020).
[45] Damien Teney, Lingqiao Liu, and Anton van Den Hengel. “Graph-structured representations for visual question answering”. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017, pp. 1–9.
[46] Tong Xiao et al. “Learning from massive noisy labeled data for image classification”. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2015, pp. 2691–2699.
[47] Danfei Xu et al. “Scene graph generation by iterative message passing”. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017, pp. 5410–5419.
[48] Kelvin Xu et al. “Show, attend and tell: Neural image caption generation with visual attention”. In: International conference on machine learning. 2015, pp. 2048–2057.
[49] Jianwei Yang et al. “Graph r-cnn for scene graph generation”. In: Proceedings of the European conference on computer vision (ECCV). 2018, pp. 670–685.
[50] Xu Yang et al. “Auto-encoding scene graphs for image captioning”. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019, pp. 10685–10694.
[51] Ting Yao et al. “Exploring visual relationship for image captioning”. In: Proceedings of the European conference on computer vision (ECCV). 2018, pp. 684–699.
[52] Rowan Zellers et al. “Neural motifs: Scene graph parsing with global context”. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018, pp. 5831–5840.
[53] Ji Zhang et al. “Graphical contrastive losses for scene graph parsing”. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019, pp. 11535–11543.
[54] Hengshuang Zhao et al. “Pyramid Scene Parsing Network”. In: CVPR. 2017.
Recommended for you
Using Mathpix and NaviLens to create accessible math flashcards
Using Mathpix and NaviLens to create accessible math flashcards
Students with print disabilities, due to blindness, low vision, learning disabilities or physical disabilities, can greatly benefit from accessible math flashcards and tutorials. Mathpix greatly reduces the amount of work required to create these by capturing text and math from a variety of sources making them ready for conversion to print or braille.