Knowledge evolution in neural networks

Nasa's Mars Rovers Family Portrait (Image credit: NASA/JPL-Caltech)
Introduction
In his book titled The Mind’s Past (1998), Michael Gazzaniga wrote: “The baby does not learn trigonometry, but knows it; does not learn how to distinguish figure from ground, but knows it; does not need to learn, but knows, that when one object with mass hits another, it will move the object … The vast human cerebral cortex is chock full of specialized systems ready, willing, and able to be used for specific tasks. Moreover, the brain is built under tight genetic control … As soon as the brain is built, it starts to express what it knows, what it comes with from the factory. And the brain comes loaded. The number of special devices that are in place and active is staggering. Everything from perceptual phenomena to intuitive physics to social exchange rules comes with the brain. These things are not learned; they are innately structured. Each device solves a different problem … the multitude of devices we have for doing what we do are factory installed; by the time we know about an action, the devices have already performed it.”
Gene transfer is the passing on of genetic information (knowledge) from parent to offspring. Although the parent might have inferior knowledge, this knowledge evolves into superior knowledge across generations. Generally, offsprings tend to have superior knowledge to their parents. This phenomenon has been studied in different fields and is an active area of research in deep learning. The paper on knowledge evolution in neural networks adopts this concept and applies it to deep networks to help them learn better and become superior to previous generations. The knowledge of the deep network is infused into a subnetwork (fit hypothesis) which is trained for g generations.
Frankle [3] describes a neural network as a set of hypotheses(subnetworks). Among these subnetworks, there exists a network that approximately describes the original dense network(lottery ticket winner). Building on Frankle’s work, Ramanujan [2] proposes a method for sampling the optimal subnetwork from an untrained network, which shows similar or superior results to a trained network with the same number of parameters. On the other hand Knowledge Evolution (KE)[1], the concept that underpins this review propagates the random selection of a subnetwork (fit hypothesis,

Figure 1: A split network illustration using a toy residual network. (Left) A convolutional filter F with
KE training and splitting
Training
For a deep network N with L layers, F filters, Z Batch norms, and fully connected layers with weight W and Bias B, knowledge evolution starts by conceptually splitting the network into two subnetworks: the fit subnetwork(

Figure 2: Binary Mask for the KELS technique
Mathematically,
The subnetworks are then randomly initialized and the network N is trained for g generations. The next generation is derived when the network is re-initialized with the fit hypothesis;
where
Hyperparameters
While training the network N, the hyperparameters (Learning rate, batch size, number of epochs) remain the same across all generations. It might be interesting to consider rescheduling the hyperparameters for future research works to check if convergence can be achieved in a relatively short training period for other generations.
Network splitting
Network splitting is achieved using two different approaches;
-
Individual weights are randomly split in each layer
-
Whole kernels for m filters are split.
(a) Weight Level Splitting (WELS)
For every layer L, a binary mask, M splits L into two exclusive subnetworks; fit hypothesis and reset hypothesis according to split rate,

Figure 3: Demonstrates the Weight level splitting technique. 3D representation of the 4D tensor clarifies the visualization
Note: The WELS approach belongs to a family of pruning methods called weight pruning. The resulting network is a sparse network
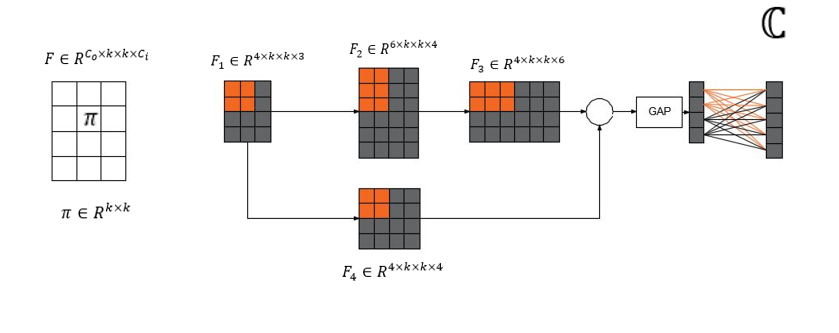
(b) Kernel Level Splitting (KELS)
The main contribution of the research paper under review is the KE and the KELS technique. KELS is different from WELS in that instead of splitting individual weights, whole kernels across m filters are split into the fit and reset hypotheses respectively. Hence for a split rate

Figure 4: Demonstrates the Kernel level splitting technique. 3D representation of the 4D tensor clarifies the visualization
KE + KELS Training Algorithm
Figure 5 outlines the algorithm for training the fit hypothesis using the Kernel level splitting technique

Figure 5: KE + KELS Algorithm
Note: A fit hypothesis is equivalent to a dense network with sparsity approximately equal to
Remember that KELS splits the network using the following scheme:"The first
Example Network
The network architecture presented in Figure 6, highlights the KE + KELS technique

Figure 6: ResNet18 & Fit-ResNet18 with
It’s very clear from the networks presented above that KE+KELS significantly reduces the number of parameters thereby reducing the number of operations. But since the training has to be done for g generations, the training time might usually be more than that for the dense network. The trade-off is that this gives a better inference cost.
Key points from KE
- The binary mask is initialized once and for all. The authors iterated on the idea of having to modify the binary mask for each generation
- The paper focuses on KE + KELS as this requires no specialized hardware or sparse linear algebra libraries
- KE works seamlessly with both regression and classification tasks
- Since the paper introduces KE and WELS, which themselves are variants of pruning techiques, the paper also disucess in detail how they relate to other pruning techniques.
Conclusion
KE may make it possible for deep learning practitioners to train deep networks on relatively small datasets. This makes Knowledge Evolution a potential strong option for medical or navigation applications; i.e. where datasets are expensive and hard to collect. KE chooses a random inferior network (fit hypothesis) and evolves its knowledge across multiple generations. To enhance performance (training and inference ), KE uses the KELS approach to split the network into 2 subnetworks. An alternative generalized approach (WELS) exists but requires specialized hardware and linear algebra libraries for efficient training. KE works seamlessly with metric learning (regression) and classification tasks. KE therefore perfectly infuses Michael Gazzaniga idea of Gene transfer in Machine Learning by depending on a small dataset to evolve knowledge while preserving the quality of the model.
References
[1] Taha,Shrivastava, Davis.Knowledge Evolution in Neural Networks.arXiv preprint arXiv :2103.05152, 2021
[2] Vivek Ramanujan, Mitchell Wortsman, Aniruddha Kembhavi, Ali Farhadi, and Mohammad Rastegari. What’s hidden in a randomly weighted neural network? In CVPR, 2020.
[3] Jonathan Frankle and Michael Carbin. The lottery ticket hypothesis: Finding sparse, trainable neural networks. arXiv preprint arXiv:1803.03635, 2018.
[4] Song Han, Huizi Mao, and William J Dally. Deep compression: Compressing deep neural networks with pruning,trained quantization and huffman coding. arXiv preprint arXiv:1510.00149, 2015
[5] Michael S. Gazzaniga. The Mind's Past(1998)
Recommended for you
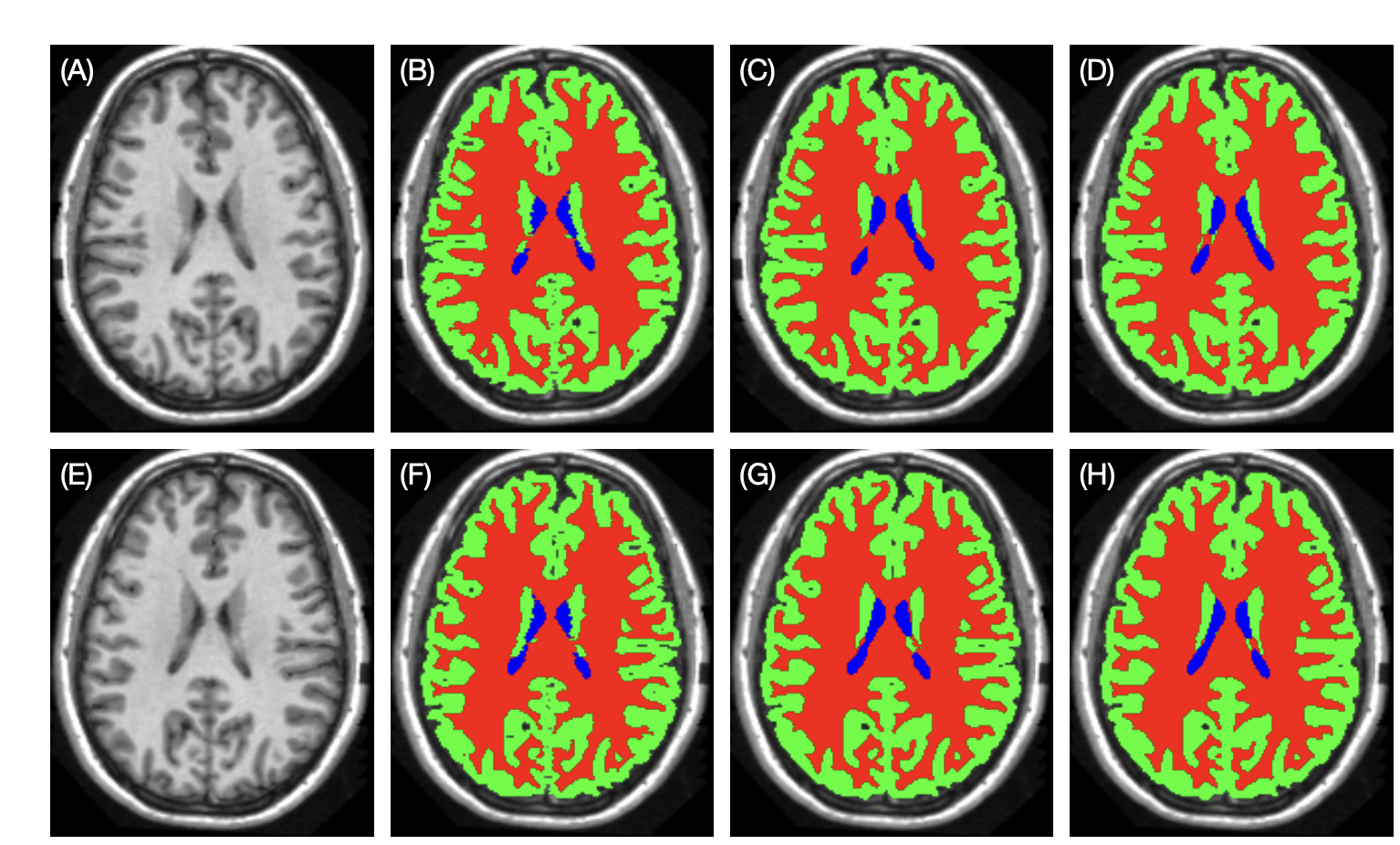
Group Equivariant Convolutional Networks in Medical Image Analysis
Group Equivariant Convolutional Networks in Medical Image Analysis
This is a brief review of G-CNNs' applications in medical image analysis, including fundamental knowledge of group equivariant convolutional networks, and applications in medical images' classification and segmentation.